

The NYT Lawsuit Against Microsoft and OpenAI Could Signal GenAI’s Napster Moment


Introduction
While reading about the myriad of lawsuits that are hitting OpenAI and Microsoft, I am more and more inclined to think that ChatGPT could face a “Napster moment”. Napster, the peer-to-peer streaming platform that was big from 1999-2001, became defined, not by its proliferation of free music, but by its loss of several copyright lawsuits that led to its shutdown. However, out of its ashes, arose an entirely new industry for legal music streaming where front runners like iTunes Store and Spotify took over from music piracy.
The recent lawsuit by the New York Times (NYT) against OpenAI and Microsoft could signal that something similar is bound to happen in the generative AI (GenAI) industry. It could take years due to the slow pace of legal proceedings. Nonetheless, in my humble opinion, The NYT lawsuit is important - even more so than the multitude of concurrent class-action lawsuits against the same defendants from artists, writers, and programmers. That is not just because of the prestigious media company’s sheer size, status, and influence but also because NYT has a strong case that cuts deep into the very fracture of the GenAI industry. In this post, I will summarize the most important key points in the complaint (in full here) and offer my perspective.
The sections of this post are as follows:
The New York Times Digital Transformation
The OpenAI-Microsoft Partnership
OpenAI is Closed
OpenAI’s Extensive Use of The New York Times Content
GPT-4 as a Copyright Theft Machine
Wrapping Up
“Making great journalism is harder than ever. Over the past two decades, the traditional business models that supported quality journalism have collapsed, forcing the shuttering of newspapers all over the country. It has become more difficult for the public to sort fact from fiction in today’s information ecosystem, as misinformation floods the internet, television, and other media. The Times and other news organizations cannot produce and protect their independent journalism, there will be a vacuum that no computer or artificial intelligence can fill.”
- Quote from The New York Times lawsuit against Microsoft and OpenAI
The New York Times Digital Transformation
Let's start out by outlining some impressive facts about The New York Times (NYT):
The news organization was founded in 1851.
As of 31 December 2022, it employed approximately 5.800 full-time equivalent workers.
In a typical year, NYT sends journalists to report on the ground from more than 160 countries.
On average, NYT publishes more than 250 original articles every day.
NYT has won 135 Pulitzer Prizes since its first Pulitzer award in 1918. That is nearly twice as many as any other organization.
By the third quarter of 2023, NYT had nearly 10.1 million digital and print subscribers worldwide.
Approximately 50 to 100 million users, on average, engage with The NYT’s digital content each week.
NYT is also one of the few traditional media outlets that has managed to keep up with the digital age. Early on, in 1996, NYT launched a website with freely available news, alongside its printed newspaper. In 2011, NYT launched a metered paywall, the business model that keeps newspapers and magazines afloat today, where users can read a few articles on the website for free before they are required to pay for a subscription to read more.
Crucially, NYT has spent significant resources to compile digital archives of all its material going back to its founding. These digital replicas of all NYT issues from 1851 to 2022 are called the “TimesMachine”. Besides the sentimental value of having such a comprehensive database of human history, NYT provides its own API that allows researchers and academics to search through the TimesMachine for non-commercial purposes. The database was never meant to be used in commercial products, and certainly not as a free lunch for big AI companies.
OpenAI & Microsoft’s Partnership
OpenAI’s existing company structure is quite confusing. Before its commercial turn, OpenAI Inc. launched in 2015 as a non-profit organization with the goal of building safe and beneficial artificial general intelligence for the benefit of humanity. In 2019, OpenAI announced that it would establish a for-profit subsidiary company, OpenAI Global LLC, to further its objectives. Shortly after the announcement, OpenAI LLC entered into a strategic partnership with Microsoft through which it has received at least $13 billion in investment to this day.
Under the Microsoft-OpenAI partnership agreement, Microsoft is entitled to 75% of OpenAI Global LLC’s profits, until the $13 billion investment is repaid in full. After that point, Microsoft will own a 49% stake in the company.
Microsoft has delivered the critical computing infrastructure to train and run models like GPT-3, GPT-4, and ChatGPT, while OpenAI has delivered the technical know-how to build the models in collaboration with researchers at Microsoft.
From Microsoft's side, the GPT technology has been used in Bing Chat, Azure OpenAI Service, and Microsoft 365 Copilot. From OpenAI's side, the GPT technology has been used in ChatGPT which includes ChatGPT Plus, ChatGPT Enterprise, and Browse with Bing. But again, the lion’s share of OpenAI’s revenue belongs to Microsoft under the partnership agreement.
So far, the partnership has been a huge success. Today, OpenAI is valued at $90 billion with projected revenue to be over $1 billion in 2024. Microsoft's deployment of large language models (LLMs) in its product line has helped to boost the company’s market cap with $1 trillion in the last year alone.
OpenAI is Closed
It was after OpenAI’s release of GPT-2 in 2018 that the organization entered into a strategic partnership with Microsoft and became for-profit. Hereafter, OpenAI has revealed progressively less information with each new model release.
Two weeks after GPT-4’s release, OpenAI published a 100-page technical report that was dedicated to showcasing GPT-4's capabilities, performance on benchmarks, and considerations regarding its safety and limitations. Outside of that, the report revealed practically nothing. On page 2 under the “Scope and Limitations of this Technical Report” section the report says:
“Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.”
Due to OpenAI’s paradoxical closedness, we don’t know which datasets GPT-4 is trained on. However, it has been estimated by experts that GPT-4 was trained on approximately 13 trillion tokens (100 tokens ~= 75 words). An enormous amount of text. But as we don’t know where GPT-4’s training data is sourced from, or where GPT-3.5’s (ChatGPT’s) is sourced from either, we have to go all the way back to GPT-3 and its accompanying research paper from 2020 to get a sense of OpenAI’s data sources. This is where things begin to get interesting.
OpenAI’s Extensive Use of The New York Times Content
Below is a table depicting GPT-3’s training data.
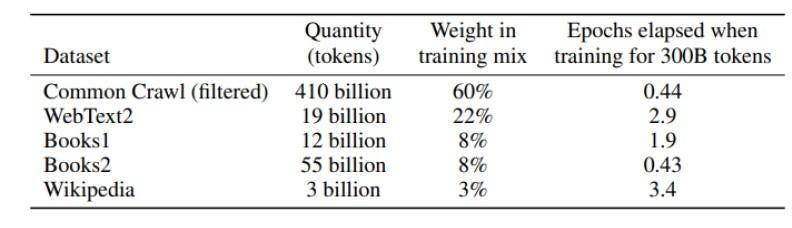
Doubts remain as to the materials contained in Books1 and Books2 although we know from the GPT-3 paper they are internet-based book corpora. We have knowledge about Common Crawl and WebText2.
Common Crawl
Common Crawl is a non-profit organization that periodically crawls the web and offers its datasets for free to anyone who is interested. The crawl archive for November/December 2023 contains 3.35 billion web pages. An unfathomable amount of data and most of it is protected by copyright. Common Crawl relies on the “fair use” copyright exemption under US law to carry out its activity. It’s worth noting that the organization does not use their datasets commercially, it only makes them available to the public. The same cannot be said for OpenAI.
Below is a snapshot of a filtered English-language subset of Common Crawl called C4.
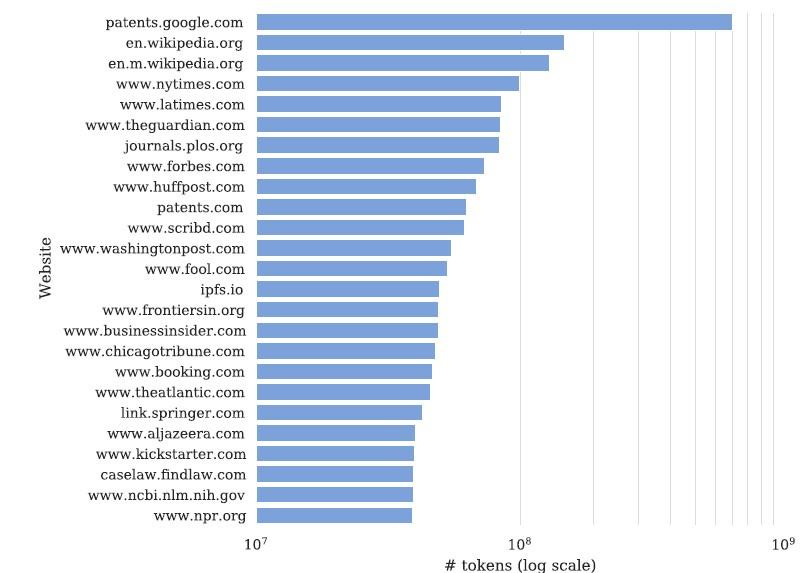
As the chart shows the domain www.nytimes.com is the most highly represented proprietary source in the dataset, only behind Google Patents and Wikipedia which are both public web domains. The NYT domain accounts for 100 billion tokens (~= 75 billion words) in the C4 dataset which according to the complaint corresponds to at least 66 million total records of content from NYT.
