

Understanding the Actual Risks of AI
The structure and key findings of the AI risk repository + comparison with risk frameworks applied by BigTech.

(Original post was featured on Michael Spencer’s AI Supremacy )
Introduction
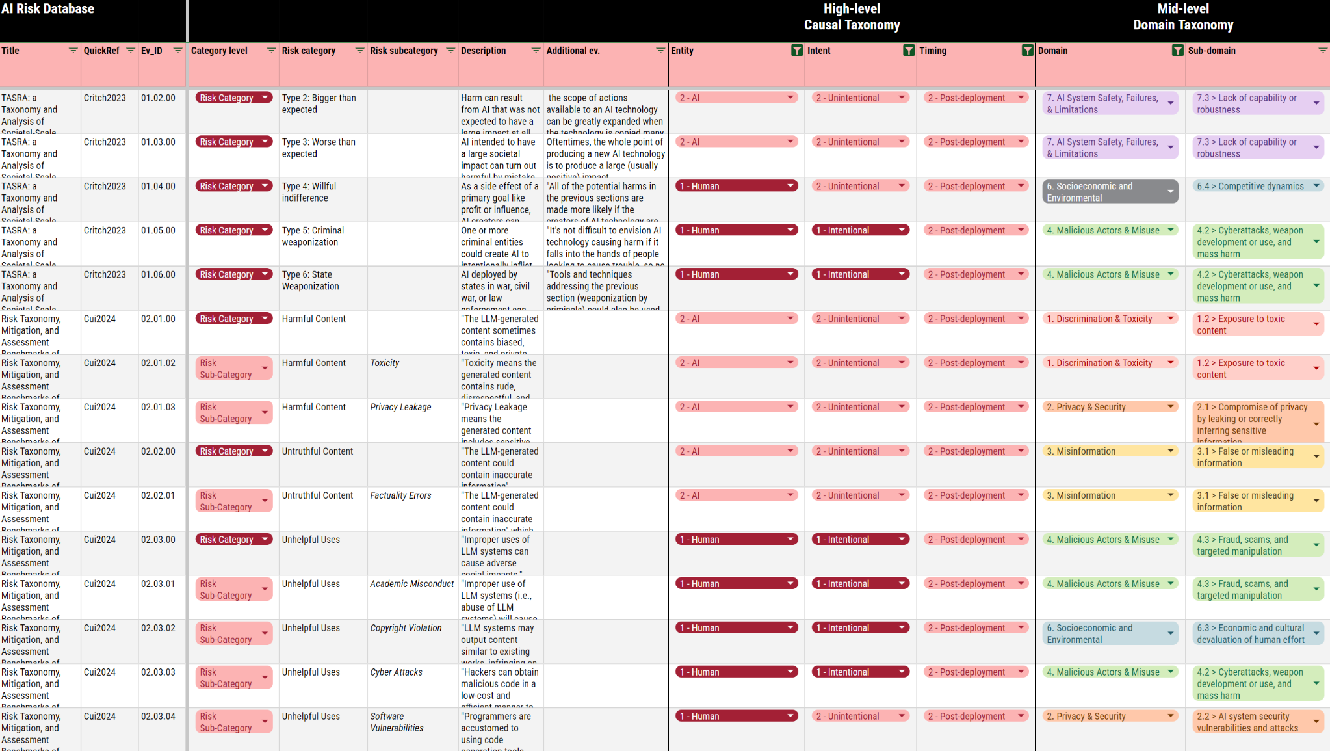
On August 14, 2024, MIT FutureTech and its partners released the AI risk repository - the most comprehensive database of AI risks assembled to date. The stated goal is to create a common frame of reference for understanding and addressing the risks from AI.
You can explore the database for yourself and read the preprint via the website here.
In this post, we will look closer into how the new database can be used in combination with the “domain taxonomy” and the “casual taxonomy" and how it differs from similar risk frameworks that are used by BigTech.
The AI risk repository was released by Peter Slattery, Neil Thompson, Alexander Saeri and Emily Grundy from MIT FutureTech in collaboration with Michael Noetel and Jess Graham from the University of Queensland, James Dao and Soroush Pour from Harmony Intelligence, Stephen Casper from MIT CSAIL, and Risto Uuk from Future of Life Institute and KU Leuven.
How the AI Repository Can Be Used & the Domain Taxonomy
As I see it, the project has two important use cases: It provides practitioners with a clear overview of the full risk landscape, and it helps to reveal research gaps in the current literature on AI risks.
As for the first point, the literature on AI risks is rich but fragmented.
There are several good risk frameworks that can be used by organizations that want to (or are legally obligated to) analyze and mitigate potential risks when deploying an AI model. However, up until now, there haven’t been any coordinated efforts to create a database like the AI risk repository which combines insights from many different frameworks. As a result, organizations, risk evaluators, security professionals, and policymakers do not have a clear overview of the full risk landscape, and risk mitigation plans and policies may be incomplete and insufficient.
Secondly, the AI risk repository reveals research gaps in the current literature on AI risks.
Building on risk classification systems from 43 peer-reviewed articles, preprints, conference papers, and other reports - that were carefully selected after screening through more than 17.000 documents - the authors identify 777 AI risks in total. Each of these risks is listed in the AI risk database with a short description from the relevant paper and a reference citation.
The risks are also grouped into 7 domains and 23 sub-domains. The authors refer to this categorization as the “domain taxonomy”.
The 7 risk domains with percentage points from highest to lowest according to how often they were cited across the 43 risk frameworks look as follows:
AI system safety, failures, and limitations (76%)
Socioeconomic and environmental harms (73%)
Discrimination and toxicity (71%)
Privacy and security (68%)
Malicious actors and misuse (68%)
Misinformation (44%)
Human-Computer Interaction (41%)
And for the 23 sub-domains:
Unfair discrimination and misrepresentation (63%)
Compromise of privacy by obtaining, leaking or correctly inferring sensitive information (61%)
Lack of capability or robustness (59%)
Cyberattacks, weapon development or use, and mass harm (54%)
AI pursuing its own goals in conflict with human goals or values (46%)
Disinformation, surveillance, and influence at scale (41%)
False or misleading information (39%)
Power centralization and unfair distribution of benefits (37%)
Exposure to toxic content (34%)
Increased inequality and decline in employment quality (34%)
Fraud, scams, and targeted manipulation (34%)
AI system security vulnerabilities and attacks (32%)
Economic and cultural devaluation of human effort (32%)
Governance failure (32%)
Environmental harm (32%)
Loss of human agency and autonomy (27%)
Lack of transparency or interpretability (27%)
Overreliance and unsafe use (24%)
Unequal performance across groups (20%)
AI possessing dangerous capabilities (20%)
Pollution of information ecosystem and loss of consensus reality (12%)
Competitive dynamics (12%)
AI welfare and rights (2%)
Of all these sub-domains, I am generally most concerned about a combination of “pollution of information ecosystem and loss of consensus reality” and “overreliance and unsafe use”. The personalized infinite scrolling loops on social media platforms like Facebook, Instagram, TikTok, and X, are both addictive and polluting and causing mental and spiritual harm, especially to the young users that are being targeted. As we can see, these two sub-domains appear to be underemphasized across the AI risk frameworks relative to other sub-domains.
